Anatomy of a Database Operation
Slides and transcript from my talk, "Anatomy of a Database Operation", at DjangoCon Europe in Dublin on 25 April 2025.
Watch the recording.

Introduction

This talk seemed like a great idea back in December 2024 when I asked the Django community for suggestions of database topics people wanted to hear about:
I'd love to be a DjangoCon Europe speaker again, because it's one of my favourite events. To that end, I'm looking for help to put together an irresistible talk submission! If you have suggestions for database/Postgres related topics that you'd really like to hear about, or burning database questions that you want to know the answer to, please let me know. I'm counting on you!
One of the suggestions was:
"how databases work and store data under the hood [so I can] build a complete mental model of what happens once you call SELECT … or INSERT."
Great idea, I thought. And then I realised just how much there was behind that one simple request!
So here goes...

I even learnt Django for the purpooses of this talk!
For demonstration purposes, I created this highly sophisticated web site that displays beer information that’s stored in a Postgres database. You can list beers, types of beer and breweries, and you can search for your favourite beer or add a new one.
But what’s happening behind the scenes when you do those things?
- How is the request passed to the database?
- How are the results retrieved and returned to you?
- How’s the data stored, retrieved and modified?
- And why should you even care?

One reason you might care is that users probably aren't happy when they see this ("LOADING, please wait...").

Or this ("DATABASE ERROR!").

This is me!
As you can see, from the diagram representing my career so far, (and as you already know if you've read my posts or watched my talks before), I have a database background.
I was a DBA for 20 years before I moved into database consultancy, and I’m now a senior solutions architect at crunchy data, working with customers to design, implement and manage their database environments.
I’m also heavily involved in the PostgreSQL community. I’m a recognised contributor to the project, I’m on the PostgreSQL Europe board of directors and I’m leading the PostgreSQL Europe diversity initiatives.

The basic PostgreSQL system architecture is the classic client/server model - the client sends a request to the server, and the server sends a response back to the client.

In our case, the client is our django app, and I'm pretty much treating the whole of the left hand side as a black box for this talk.

To perform a database operation, we need to send a request over the network to our Postgres database.
Postgres executes the request - accesses and/or manipulates the data, and sends the results back to the user.
Let’s look at each of those steps.
1. Send a Request to the Database

First, we need to send a request to the database.

As an example, we’ll open the beer types page.
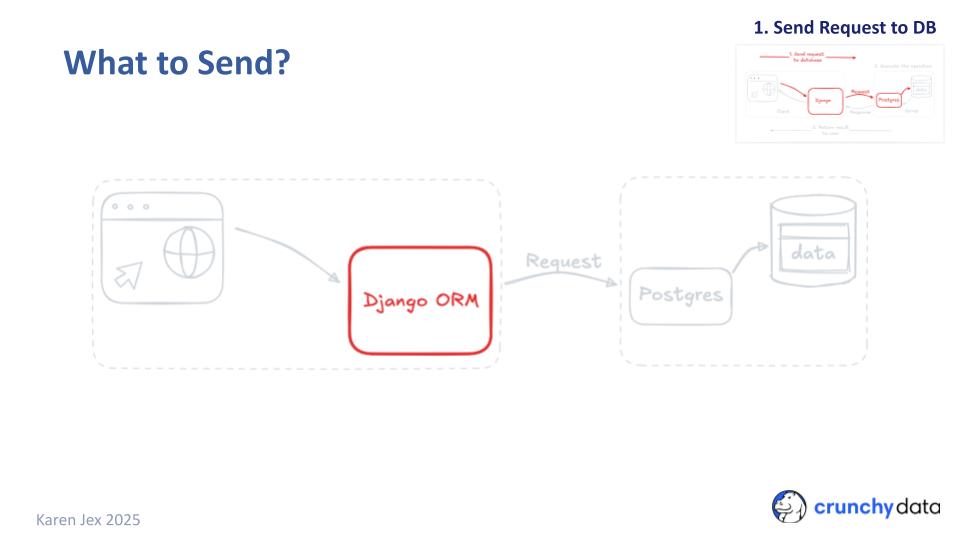
For the page to open and display the types of beer, we need to figure out what’s going to be sent to the database. Unless you’re exclusively writing custom SQL queries, this is where the Django ORM comes into play

I certainly wasn't going to try to teach the DjangoCon Europe audience anything about Django, because that’s definitely not my area of expertise, so I don't go into details about the ORM here.
Note that I’m also not attempting any kind of optimisation for the purposes of this talk. In this case, the view just selects everything from the beertype table and orders it by name:
Beertype.objects.order_by("name")
It generates this SQL statement:
SELECT "beerdirectory_beertype"."id",
"beerdirectory_beertype"."name",
"beerdirectory_beertype"."description"
FROM "beerdirectory_beertype"
ORDER BY "beerdirectory_beertype"."name" ASC;

You’ll need a database connection, of course, if there isn’t already one open. The Postgres server process (just called postgres) manages the database files, accepts connections to the database and performs database actions on behalf of the clients.

For some reason, the Happy Mrs Chicken game from Peppa Pig came to mind as an analogy for the Postgres server process...
Happy Mrs Chicken represents our original, supervisor Postgres server process.
She listens on a port (5432 by default) for incoming connections.
Once something connects on that port, she lays an egg forks a new postgres server process for the connection.
From that point on, the client and the new server process communicate without Happy Mrs Chicken the original postgres server process being involved.
We talk about the combination of the server process and associated client process as a Postgres session.

Once you have your database connection, the original postgres process moves aside to wait for new connection requests.

And of course, there could be other client connections at the same time, but we’ll just concentrate on ours for now.

On a related topic we generally try to keep concurrent connections to Postgres in the low hundreds (the default is 100) because a high number of client connections can result in a lot of resource usage, and because rapid creation and destruction of sessions is expensive.
You can implement connection pooling between the client and the database to reuse and buffer connections between the database and the application, and reduce the creation and destruction of processes.
This could be on the application side, or you could use a Postgres connection poooler such as PgBouncer.

Now we can send the query to postgres to be executed.
2. Execute the Operation

Which takes us to the step where Postgres actually executes the database operation. We’ll spend most time looking at this part.

As a reminder, this is the query we’re executing:
SELECT "beerdirectory_beertype"."id",
"beerdirectory_beertype"."name",
"beerdirectory_beertype"."description"
FROM "beerdirectory_beertype"
ORDER BY "beerdirectory_beertype"."name" ASC;
It's selecting all of the columns from the beertype table and ordering by name.

Before it can return the results to the user, Postgres needs to go through several steps to execute the query:
- Parse the statement, checking for syntax errors etc.
- Transform and Rewrite the statement to take things like views into account.
- Plan the query to figure out the best way to retrieve the data.
- Execute the plan: Access the table(s), fetch data blocks, apply filters, sort, aggregate etc.

The parse step is where Postgres will check things like:
- Are there any syntax errors?
- Do the columns, tables etc. that the query is trying to access exist?
- Do you have permission to access those objects?

We’ll assume the SQL statement generated by the Django ORM is correct, but the parse stage would be where you'd see something like
ERROR: relation "beerdirectory_beertypes" does not exist
if there was a misspelt table name.

The transform stage interprets things like views to understand which tables, functions etc. it actually needs to access.
The rewrite phase modifies the query to take rules such as row level security into account.
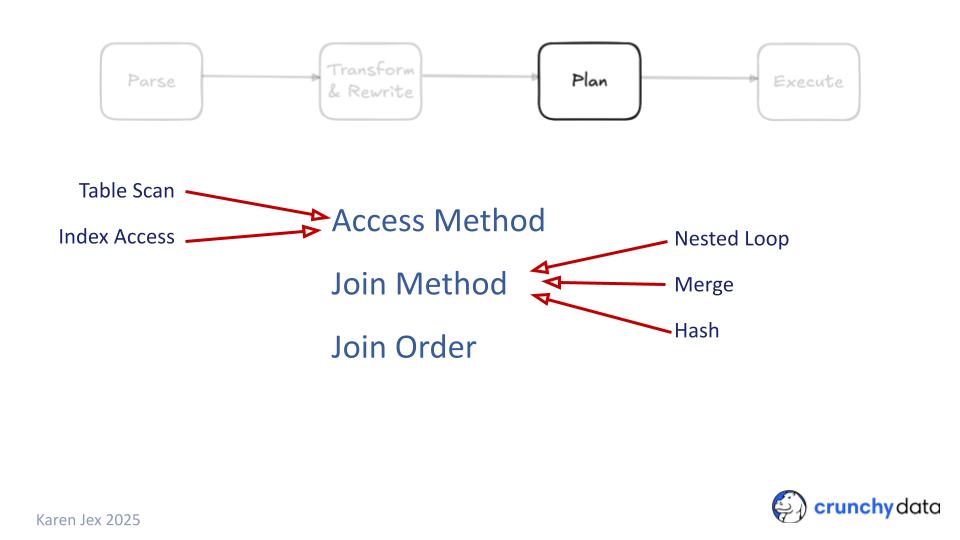
The planning phase generates the execution plan - the details of the way in which Postgres is going to get the results of the query.
SQL is declarative - you tell Postgres what you want, but not how to do it.
The execution plan will include information such as:
- How is it going to access the tables?
Is it going to use an index or scan the whole table? - Will it join the tables using nested loops, merge or hash joins?
- What order is it going to join the tables?
I recommend looking out for the recording of Adam Johnson's talk "Data-Oriented Django Drei" that he gave earlier in the conference. He spoke about execution plans, and gave a really good overview of some of the elements.

I know that execution plans can be pretty daunting to read and understand until you get used to them.
When I asked people what kind of things they wanted to hear most about in this talk, almost half said query execution plans. I might need to propose a workshop on that for next time, but for now, I'll give a few hints on understanding execution plans.

You can use explain to see the execution plan for a query. I’ve just added 2 options here:
-
ANALYZE means Postgres will actually execute the query, so it can give you information about what it's done rather than just what it plans to do.
Be careful if your query makes changes and you don’t want them to be permanent - put it in a transaction and ROLLBACK. - BUFFERS helps identify which parts of the query are the most I/O intensive.

The execution plan that's generated is made up of nodes, where each node is one of the steps in the plan. This is one of the nodes from the plan generated by our query:
-> Seq Scan on beerdirectory_beertype (cost=0.00..3.00 rows=100 width=107)
It tells us what the node does (sequential scan), the object it accesses (the beertype table), and shows estimated statistics:
-
Cost information:
- Startup cost (cost to bring back the first row).
- Total cost (cost to bring back all rows).
- Estimated row count.
- Average row width.
Plus, if you've used ANALYZE, you'll see the actual runtime statistics.

This is the whole plan:
QUERY PLAN
--------------------------------------------------------------------------
Sort (cost=6.32..6.57 rows=100 width=107) (actual time=0.227..0.235 rows=100 loops=1)
Sort Key: name
Sort Method: quicksort Memory: 38kB
Buffers: shared hit=5
-> Seq Scan on beerdirectory_beertype (cost=0.00..3.00 rows=100 width=107) (actual time=0.039..0.070 rows=100 loops=1)
Buffers: shared hit=2
Planning:
Buffers: shared hit=127
Planning Time: 1.393 ms
Execution Time: 2.260 ms
We can see 2 nodes: “Sort” and “Seq Scan”.
Sort is the root node, and the results of indented nodes below it will be fed into it.
In this case, that's the Seq Scan on the beertype table. This reads the whole table, which is to be expected since we asked it to return all the rows.
beertype is a small table, and Sort Method: quicksort Memeory shows us that the sort is being done in memory.

Let's take a slightly more complicated query, this time getting a list of beers where beer type is Irish Red Ale:
EXPLAIN (ANALYZE)
SELECT beer.id,
beer.name
FROM beerdirectory_beer beer
INNER JOIN beerdirectory_beertype beertype
ON beer.beer_type_id = beertype.id
WHERE beertype.name = 'Irish Red Ale'
ORDER BY beer.name;
I've removed buffers, just to make output easier to read.

Here's the full plan:
QUERY PLAN
-------------------------------------------------------------------------------------------------
Sort (cost=32.71..32.77 rows=23 width=26) (actual time=0.216..0.219 rows=12 loops=1)
Sort Key: beer.name
Sort Method: quicksort Memory: 25kB
-> Nested Loop (cost=4.46..32.19 rows=23 width=26) (actual time=0.064..0.106 rows=12 loops=1)
-> Seq Scan on beerdirectory_beertype beertype (cost=0.00..3.25 rows=1 width=8) (actual time=0.029..0.039 rows=1 loops=1)
Filter: ((name)::text = 'Irish Red Ale'::text)
Rows Removed by Filter: 99
-> Bitmap Heap Scan on beerdirectory_beer beer (cost=4.46..28.71 rows=23 width=34) (actual time=0.029..0.057 rows=12 loops=1)
Recheck Cond: (beer_type_id = beertype.id)
Heap Blocks: exact=10
-> Bitmap Index Scan on beerdirectory_beer_beer_type_id (cost=0.00..4.45 rows=23 width=0) (actual time=0.013..0.013 rows=12 loops=1)
Index Cond: (beer_type_id = beertype.id)
Planning Time: 0.864 ms
Execution Time: 0.283 ms
We can see several nodes here:
- A Bitmap Index Scan feeds into a Bitmap Heap Scan on the beer table
- A Seq Scan on the beertype table and the Bitmap Heap Scan on the beer table feed into a Nested Loop (join)
- The Nested Loop in turn feeds into the root Sort.

A brief aside before talking through the steps in the plan: Postgres tables and indexes are made up of 8k pages (unless you've recompiled Postgres with a different page size).
The slide shows a diagram, taken from the Postgres docs, that represents the layout of a page.
Data fills in free space from the end, towards the beginning of the page.
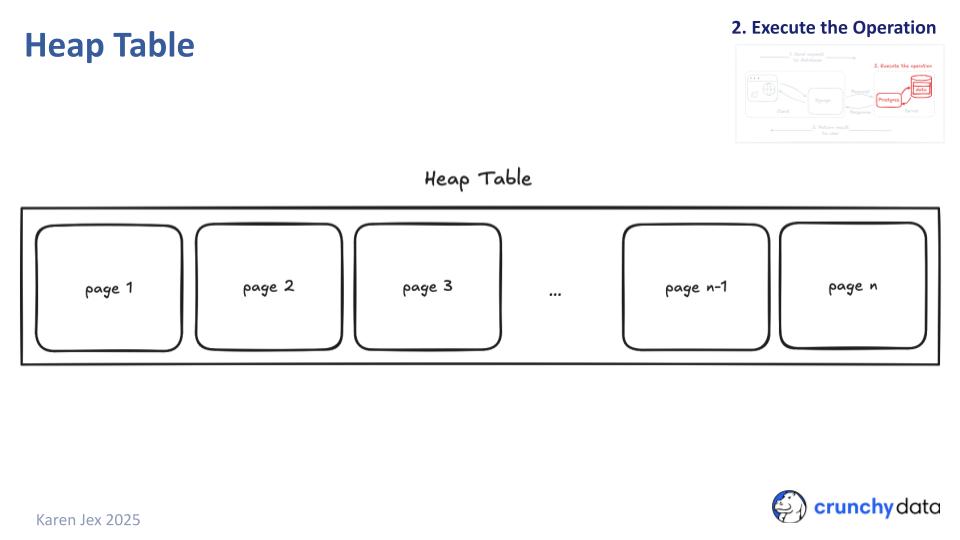
A Postgres table, by default is a heap table; an array of data pages, with rows stored in no particular order.

In addition to the information shared by Adam in the talk that I already mentioned, Haki Benita expertly set the scene on Postgres indexes in his talk " How to get Foreign Keys horribly wrong in Django" earlier in the conference, so I didn’t need to go into too much detail here.
As you already heard, there are multiple index types in Postgres, but b-tree is the default. It's a multi-level tree structure with:
- A single root or metapage.
- One or more levels of (double-linked) internal pages that each points to the next level down in the tree.
- A single level of (double-linked) leaf pages that contain tuples that point to the actual table rows.
The diagram on the slide represents the beertype index on our beer table, so the leaf pages contain pointers to the rows containing each of the different beer types. I've just shown the entries for Red Ale.

Now, Postgres has to put the plan into action.

The first step is the sequential scan (Seq Scan) on the beertype table.

A sequential scan checks through each of the pages in a table to find the rows that match the filter. People are often taught that sequential scans are bad, and it's true that it can sometimes indicate for example that you neeed to add an index. On the other hand, if you’re requesting a large enough subset of the data in your table, it can actually be the most efficient way to do it.
Remember also that some of the blocks may be in memory, in the shared buffers, so Postgres might not need to go to disk for all of the data.

In this case, we’re looking for the single row for “Irish Red Ale” in the beertype table. You might wonder "Why not use an index?", but the whole table only contains 2 pages, so Postgres worked out that it would be faster just to scan those two pages than to look up the value in the index.

Next is a Bitmap Index Scan of the index on the beer table’s beertype id column.

This traverses the index tree to find the entries that match the filter (i.e. the beertype id that matches the value for Irish Red Ale) and creates a bitmap of potential row locations. That will usually be rowids, i.e. a pointer to the actual row location, but may sometimes be a pointer to an entire page.

These row locations are passed to the Bitmap Heap Scan node, which can then get the actual row data from the table pages.

So far, we've just selected data.
What if we’re modifying data? What if someone adds a new beer, or a new beer type?

For example, if we INSERT a new beertype called “IPA”:
INSERT INTO beertype (name)
VALUES ('IPA');
Postgres will find a page in the table that has some free space (remember the page layout we saw previously). It will add a new row in the space available, along with a pointer to the new row. If there’s no space in any of the existing pages, it will create a new page.

Once the transaction is committed, the new beertype will be visible to other sessions.
The essential point of a database transaction is that it bundles multiple steps into a single, all-or-nothing operation.
- It consists of one or more operations or statements
- It starts with a BEGIN and ends with either
- COMMIT (all of the operations in the transaction are permanently applied to the database) or
- ROLLBACK (all of the operations in the transaction are cancelled).
- The changes made in one transaction are only visible to other transactions after they are committed.
Links: Database transactions in the Django docs and in the Postgres docs.

Most Postgres clients, Django included, enable autocommit mode by default.
This means that each statement starts a transaction and automatically COMMITs at the end. You need to specify if that’s NOT what you want.

If we delete the row we just inserted:
DELETE FROM beertype
WHERE name = 'IPA';
it doesn’t physically get removed (yet), Postgres just marks it as dead. It will be removed later during a vacuum operation once Postgres is sure it's no longer needed.

Updating the row:
UPDATE beertype
SET name = 'India Pale Ale'
WHERE name = 'IPA';
is actually a combination of an insert and a delete. A copy of the row will be created containing the new information, and the old version of the row will be marked as dead.

The way UPDATES and DELETES are handled are part of the Postgres MVCC (Multiversion Concurrency Control) mechanism.
This is how Postgres maintains data consistency internally and gives transaction isolation, preventing a SQL statement from seeing inconsistent data due to updates by concurrent transactions.
The main advantage of the MVCC model is that locks for reading data don’t conflict with locks for writing data, so
Reading never blocks writing and writing never blocks reading.
The tradeoff is that we need to periodically vacuum tables to remove dead tuples to minimise table bloat.
3. Return Result to User

This brings us to the final step - returning the results to the user. Postgres returns the results to the client (Django) so they can be presented to the user.

In the case of our super simple webpage, that means displaying the types of beer to the user.

I'm not spending much time on this part, but there are some things to consider re. returning the results. In particular, don’t retrieve more data than you actually need.
Aside from not wanting to do more I/O than you need to on the database, there’s network involved in this step. You don’t want users to be hanging around waiting for data to be transferred if it’s not actually needed, or if it’s not needed yet.
- If you’re not going to use certain columns, don’t bother selecting them.
- If you don’t need to display all rows, or you don’t need to display them all at once, just fetch the rows you actually need.
When I was a DBA, the database was blamed for everything, but we preferred the mantra “It’s always the network”!

I added a couple of hopefully useful bits of related information in case I got time to share them at the end of the talk:

Firstly: Postgres configuration parameters can have a big impact on database operations and performance. I did a whole talk on that at DjangoCon Europe in Edinburgh in 2023.
For this talk, I'll just share a couple of logging parameters, which are particularly useful if you want more info about what’s going on in the database. You can find out more about them in the Postgres docs and in the default Postgres configuration file (postgresql.conf) which contains useful comments.

log_min_duration statement
Disabled by default, this will write any completed statements that ran for longer than the specified amount of time to your logs. This can help you to track down unoptimized queries in your applications. Set it to whatever counts as “too long” for your system. It's useful for dev/debugging purposes, but may generate too much noise in your logs in a production system.

log_line_prefix
A string added to the beginning of each Postgres log line. By default, log lines are prefixed with just the timestamp and process ID, which isn't super useful for debugging.
To get more information about who’s doing what, where, when etc. you can include many different fields and any text you choose.
Example: log_line_prefix='%t:%r:%u@%d:[%p]: '
The example I’ve here contains:
- %t Timestamp
- %r Host connecting from
- %u Database user name
- %d Database connecting to
- %p PID
- A space at the end to separate the prefix from the actual log message for legibility.

Secondly, after Haki's talk, someone asked how to learn SQL.
Obviously, I'm biased because I work for Crunchy Data, but I had to mention the Crunchy Data Postgres Playground - Postgres in your browser along with a selection of tutorials.
It's a fully functioning Postgres cluster, but please don't use it as your production database!

This is the Learn SQL tutorial, which is probably a good place to start.

Additional Resources:
- Crunchy Data Blogs:
- PostgreSQL Docs (current version)
- Django Docs:

References:
- Postgres architecture
- MVCC
-
Transactions in the Postgres docs
Transactions in the Django docs -
EXPLAIN syntax
using EXPLAIN - Logging parameters
- PgBouncer
- Original Dataset

Thank you for reading!
Get in touch, or follow me for more database chat:
LinkedIn: https://www.linkedin.com/in/karenhjex/
Mastodon: @karenhjex@mastodon.online
Bluesky: @karenhjex.bsky.social